
If you are on this page, I assume that you have already set up your Google Cloud project as well as created your service account. If you haven’t, click here.
You can use Google Cloud Long Audio API to turn text longer than 5000 bytes into its audio version. However, instead of having the output directly on your computer, the output will be stored in Google Cloud Storage.
Please note that currently, you can only use the Long Audio API for texts in English and Spanish.
Let’s get started!
1. On your Google Cloud console, click on the menu in the top left corner of the page. In the Cloud Storage section, click “Bucket”.
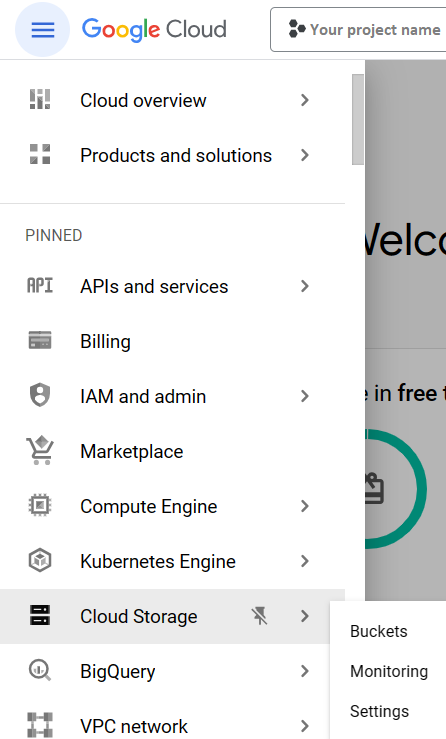
2. In the Buckets tab, click on “Create”.
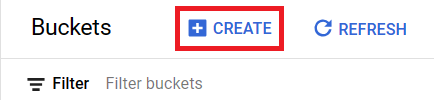
3. Name your bucket. Choose the region where you want to store your data. Prevent public access to Restrict data from being publicly accessible via the Internet. Fill in the rest of the fields based on your preference.

4. Next, on your bucket page, click on “Permission”.
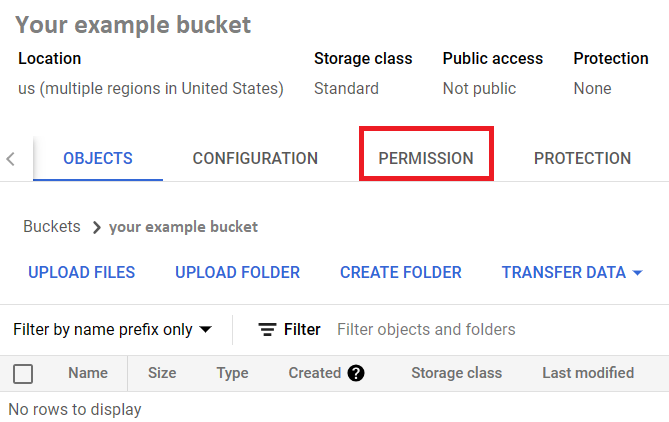
5. You find that your project account has been an owner, editor, and viewer of the bucket. However, you need your service account to be granted access as well so that you can access the Cloud Storage bucket with your Python command. So, click on “Grant Access”.
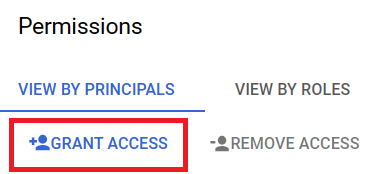
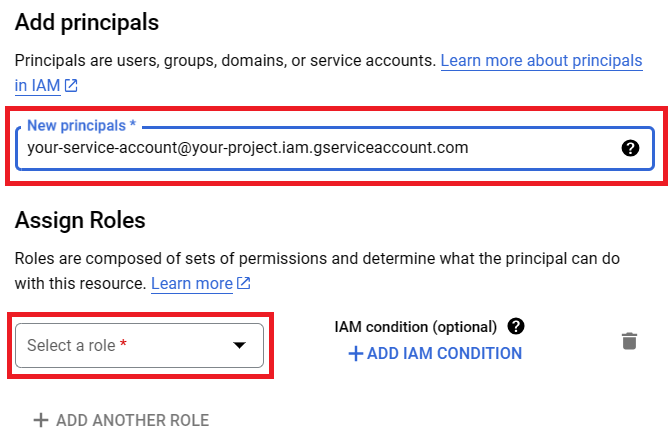
6. Enter the service account email (you know where to find it: top left corner menu -> APIs and services -> Credentials). Next, assign two roles to your service account, select “Storage Object Viewer” and “Storage Object Editor” (under the Cloud Storage grouping).
7. Next, open VS Code or your Python code editor application, and if you haven’t installed the client library, install it with the following command on your prompt:
pip install --upgrade google-cloud-texttospeech8. Create a *.py” file for your script. Copy the following code:
If you want to write your text in a *.txt file instead of writing it directly on your Python script, read the Appendix section at the end of this post.
# YOU CAN USE THIS FOR AUDIO LONGER THAN 5000 BYTES (ONLY SUPPORTS ENGLISH & SPANISH)
# ADJUST JSON KEY PATH
# ADJUST AUDIO CONFIGURATION
# ADJUST TEXT
# ADJUST OUTPUT PATH ON CLOUD STORAGE
from google.cloud import texttospeech
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]="path/to/your/service-account-key.json"
# Create a function to synthesize long audio:
def synthesize_long_audio(project_id, location, output_gcs_uri):
client = texttospeech.TextToSpeechLongAudioSynthesizeClient()
input = texttospeech.SynthesisInput(
text="Hellow, World!"
)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.LINEAR16
)
voice = texttospeech.VoiceSelectionParams(
language_code="en-US", name="en-US-Neural2-J"
)
parent = f"projects/{project_id}/locations/{location}"
request = texttospeech.SynthesizeLongAudioRequest(
parent=parent,
input=input,
audio_config=audio_config,
voice=voice,
output_gcs_uri=output_gcs_uri,
)
operation = client.synthesize_long_audio(request=request)
print("Finished processing, check your GCS bucket to find your audio file!")
# Set the project ID, location, and output GCS URI:
project_id = "your_project_ID"
location = "your_location"
output_gcs_uri = "gs://your example bucket/output name.wav"
# Run the function:
synthesize_long_audio(project_id, location, output_gcs_uri)(1) Replace “path/to/your/service-account-key.json” with the actual path to your service account key JSON file. Remember where you store the key file.
(2) Within the input variable, replace “Hello, World!” with your actual text.
(3) In the audio variable, choose your language_code and voice name. You can go to the Google Cloud Text-to-Speech API product overview and test all the voices available for the language of your text (in this case, English or Spanish), in the Demo section. You can find the language_code and voice name of your choice in the JSON script below the voice settings.
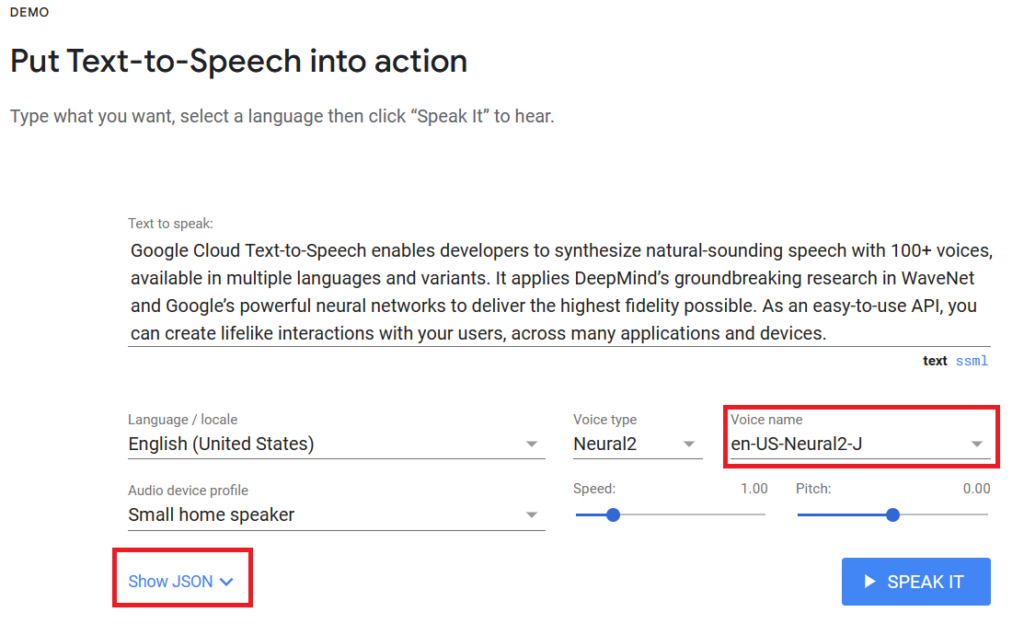
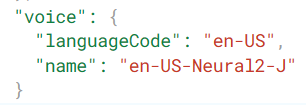
(4) Replace “your_project_ID” with your actual project ID.
(5) Choose your API request location, and replace “your_location” with the location of your choice. For example: “global“: The global endpoint; “us-central1”: The region corresponding to Iowa, USA; “europe-west1“: The region corresponding to Belgium; “asia-east1“: The region corresponding to Taiwan.
(6) Set your output_gcs_uri path. After “g://” should be your bucket name, and replace “output name.wav” with the output file name you want.
Once your parameters are all set, you can run the code and find the audio output file in your Google Cloud Storage bucket.
Congratulations! You have done all the essential steps to create a long audio through Google Cloud Text-to-Speech with Python. Now you can create long audio files from texts.
Appendix
Before using Google Cloud Text-to-Speech API, I usually proofread and edit the text to adjust the language and the flow of the speech. I don’t do this process on my Python script, but on a text file (*.txt).
To keep the script as clean as possible, rather than putting all the text in it, I use this code:
# Open the .txt file
file_path = 'your text file folder/your text file name.txt'
with open(file_path, 'r', encoding='utf-8') as file:
mytext = file.read()
# Close the file
file.close()The variable “mytext” contains the text from the *.txt file. Therefore, the rest of the script will look like this:
from google.cloud import texttospeech
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]="path/to/your/service-account-key.json"
def synthesize_long_audio(project_id, location, output_gcs_uri):
client = texttospeech.TextToSpeechLongAudioSynthesizeClient()
input = texttospeech.SynthesisInput(
text=mytext
)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.LINEAR16
)
voice = texttospeech.VoiceSelectionParams(
language_code="en-US", name="en-US-Neural2-J"
)
parent = f"projects/{project_id}/locations/{location}"
request = texttospeech.SynthesizeLongAudioRequest(
parent=parent,
input=input,
audio_config=audio_config,
voice=voice,
output_gcs_uri=output_gcs_uri,
)
operation = client.synthesize_long_audio(request=request)
print("Finished processing, check your GCS bucket to find your audio file!")
project_id = "your_project_ID"
location = "your_location"
output_gcs_uri = "gs://your example bucket/output name.wav"
synthesize_long_audio(project_id, location, output_gcs_uri)